

This week I was approached by a (valued) customer that was convinced that he had found a problem in the DBFCDX driver in X# and the customer had a reproducible example of a seek in a DBF that failed in X# but worked in Visual Objects(VO). And to be honest, I also had the feeling that this could indeed be a bug
In this (long) article I would like to explain the problem and also give a little bit of background info about CDX indexes and sorting.
So I loaded the code from the customer and indeed the seek failed in X# and succeeded in VO.
Then I ran an internal command that dumps the contents of a tag inside a CDX to a text file, so I could inspect the various index pages.
After that I recreated the index in X# and dumped that index too and I found that there was difference in the sort order.
I thought: Bingo there is indeed a problem in our sorting routine and I confirmed the bug to the customer. But I was wrong....
The difference that I found between the index dumps was that keys such as SA50_FX1000 and SA50_FX_TD were sorted in a different order in the two index files.
The next day I had a closer look to the problem and recreated the index file in VO and also in FoxPro and found that the order of the keys in both VO and FoxPro on my machine was exactly the same as the order of the keys in X#. So X# was doing it exactly as expected. But what was the problem then ?
My first suspicion was that that somehow the machine of the customer had different windows codepage/collation settings and that this caused the problem. But that was also not the case.
Before I continue with the cause of the problem and how I found it, it is now time give a bit of background informations on how indexes are sorted in Clipper, VO, XBase++ and FoxPro.
DBF files and sorting of the indexes
In an earlier article I have already explained a bit about codepages and Unicode. In short: strings are stored in DBF files in bytes. A single byte in the index header is used to store the codepage that was used to create the file. This is not the normal codepage number (437, 850, 1252 etc), but a number between 0 and 255. For example 0x01 = US Dos, 0x03 = Windows Ansi, 0x64 = Eastern European DOS. In DOS this was a DOS codepage, in windows a Windows codepage.
When creating an index in a product in DOS in Clipper then the index would be created based on the numeric order of the bytes in the keyvalue. If you wanted another sort order you had to link in a so called "Nation object" file. This object file contained a weight table. During sort operations (indexing, sorting but also ASort() and other string comparisons) this weight table would be used to lookup each byte from the string and determine its weight. Since sorting always has to do with at least 2 strings then the weights from the Left hand side were compared with the weights in the right hand side. That determined the sort order.
The following table illustrates this for a 2 byte string with a fictional weight table:
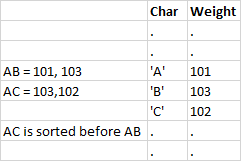
So using the weigth table AC could be sorted before AB.
When VO was created then the VO development team had to consider using files in Clipper DBF format and their indexes at the same time from Clipper (DOS) and from VO (Windows). To make sure that the contents of the files were sorted in the same order the team introduced the concept of a Collation and a series of nation DLLs that contained the windows equivalent of the special object files that Clipper used. To use that in your application you could specify:
{source}SetNatDll("GERMAN.DLL")
SetCollation(#Clipper){/source}
The first line tells the VO runtime to load a nation DLL that contains the translated strings for messages in the runtime (such as "Press any key to continue" for the WAIT command) as well as the weight tables. This does NOT activate these weight tables.
The second line tells the VO runtime to use the loaded weight table for the sorting. If you do not load a nation DLL first then a default weight table is used where each character has a weight that is the same as the byte number (A = 64, B= 65 etc). The rest works just like in Clipper.
The alternative setting is SetCollation(#Windows) (which is the default).
If you use that setting then string comparisons are handled by the CompareString() function in the windows kernel:
{source}_DLL FUNC CompareString(Locale AS DWORD, dwCmpFlags AS DWORD, lpString1 AS PSZ,;
cchCount1 AS INT, lpString2 AS PSZ, ccCount2 AS INT)AS INT PASCAL:KERNEL32.CompareStringA{/source}
This CompareString takes a LocaleId as first parameter and a flags parameter that is set to SORT_STRINGSORT (0x00001000). The other parameters are the strings to compare and their lengths.
The original implementation in VO for the 1st parameter was to use the GetSystemDefaultLCID(). Howver in 2000 this was changed (upon user request) to GetUserDefaultLCID().
This settings works fine when all the users accessing the file have the same settings in Windows. However if workstations were set to dfferent locales (for example Polish on one and German on another) then index corruption could occur.
But also if both computers were using German and one computer had selected (in the control panel) to use the normal sort order and another station to use the "German Phonebook' then also corruption could occur.
Many developers discovered this problem and decided that it was better to not rely on their users windows preferences used SetCollation(#Clipper) and a nation module for their applications.
When I worked in the VO Development team we solved this problem by adding a runtime function that allows you to set the LocaleId that is used for string comparisons with the new function SetAppLocaleId(). Some of the VO developers picked this up, but many others kept using the clipper collation: "if it ain't broken, don't fix it".
In X# we had to deal with this as well and on top of that we also had to deal with Ansi , Unicode conversions when working with DBF files.
What we do in this area is:
- We have imported the sort tables from Visual Objects as resource
- We have added the SetCollation function from Visual Objects (and enhanced it, see below)
- When you select #Clipper collation then for each string comparison we do the following:
- Convert the string from Unicode to Ansi
- Use the weight table to compare the bytes in the Ansi string.
- This sounds "expensive" in terms of performance, but that is the only way to be 100% compatible
- If you have selected SetCollation(#Windows) then we do:
- Convert the string from Unicode to Ansi bytes as well
- Call the CompareString() function just like in Visual Objects. We are also defaulting to GetUserDefaultLCID() but we also allow you to set this locale with SetAppLocaleId()
Please note that this is also done for string comparisons that are not related to indexes, at least when you have set the compiler option "Compatible String Comparisons". Otherise the sort order for ASort() and other string comparisons would be different from VO.
We have added 2 new options for SetCollation()
- #Unicode : This does a Unicode String compare with the string comparison routine in the .Net runtime. So no Unicode -> Ansi translation is done
- #Ordinal: This does an ordinal string compare, so basically each Unicode character is considered as a unsigned 16 bit number and these numbers are compared. This is by far the fastest.
These last two settings should NOT be used in apps that access DBF files, but could be usefull for apps that work with SQL data only. Especially if your application mixes characters from different character sets.
Back to the customers problem
Lets get back to the problem from the customer. That customer had sent me some test code in Visual Object and X# and this test code did not contain any reference to SetCollation or SetNatDLL(). So I assumed that the file was created with windows collation. But since I found that recreating the file on my machine produced a different result than the file that I received from the customer that probably meant that the settings on the customers machine were different from the settings on my machine.
So I asked the customer to run some code on his machine to display the current codepage and some other values, and to my surprise these values were the same in both VO and X#. So that could not explain why the seek failed in X# and not in VO.
But in the next email my customer explained that he has the habit of setting SetCollation to #Clipper and using the German nation DLL. But since the test program was not writing anything in the index he did not include that in the test code, and he was convinced that set the collation was was not needed because the VO code could find the keys without problems.
And then I started to understand what was happening.
I tried to recreate the index with X# on my machine with the same #Clipper collation and German nation DLL table and the keys in the file were created in exactly the same sort order as in the original index file from the customer.
So why did the test program in VO find the key and did the same test program in X# Fail?
There must be an explanation for this (and there was a few hours later)
Below is a part of a dump of the contents of the customers index. We are seeking for the key "SA50_FX1000"
I have created this "dump" of the index with an undocumented (and unsupported !) function in the RDD that we created in X#:
DbOrderInfo(DBOI_USER+42)
This dumps the contenst of the current tag to a text file. (CDX) index files are made of 2 types of pages. The FoxPro documentation calls thes "interior" pages and "exterior" pages. We refer to these in our RDD as "Branch pages" and "Leave pages". In a CDX the Branch pages contain references to other pages and the Leaf pages contain the actual key - record number pairs. Very small indexes may consist of only Leaf pages, but most indexes have one or more levels of branches and a single level of leaves.
The pages on a level form a linked list and have references to their left and right siblings.
Branch pages also contain key values.These key values describe the pages that they are pointing to.
The maximum number of keys is determined by the size of the key. Each page is 512 bytes. That is why there is a maximum key size. The maximum key size is therefore 240, so at least 2 keys will fit on a branch page. The remaining 32 bytes are for the record numbers, child page references, sibling page referencs and some houskeeping data.
The root page of my customers index looked like this:
{source}Root Page 003400, # of keys: 2, MaxKeys: 17
Left page reference FFFFFFFF
Item 0, Page 000E00, Record 1889 : P50LFX2000
Item 1, Page 003200, Record 1016 : ZINSEN
Right page reference FFFFFFFF{/source}
This is the first page in the index. It is a special branch page. It does not contain actual keys but only references to other pages in the index.
The keys on this page are the last keys found on the pages one level below this, so ZINSEN is the last key on page 03200. Since we are looking for a key that is larger than P50LFX2000 we need to continue our searcg on page 03200.
{source}Branch Page 003200, # of keys: 10, MaxKeys: 17
Left page reference 000E00
Item 0, Page 002E00, Record 9 : PER4M
Item 1, Page 003000, Record 478 : PGML2
Item 2, Page 003600, Record 406 : PROF.REGENSCHIENE
Item 3, Page 003800, Record 438 : PTAZB41N
Item 4, Page 003A00, Record 1419 : S40_FN_1
Item 5, Page 003C00, Record 1782 : S50_SSPF
Item 6, Page 003E00, Record 1547 : SA60_FN_1_TS
Item 7, Page 004000, Record 359 : SSFRSX
Item 8, Page 004200, Record 168 : ZANZPREDI
Item 9, Page 004400, Record 1016 : ZINSEN
Right page reference FFFFFFFF{/source}
This is a normal branch page. It is the last page of the pages on this level (the right page link is FFFFFFFF)
We seek the key SA50_FX1000, so we have to continue on page 003E00 on the next level.
{source}Leaf Page 003E00, # of keys: 91, Free Bytes 3
DataBytes: 3, RecordBits: 14, DuplicateBits: 5, TrailBit: 5
Left page reference 003C00
Item 0, Record 1455, Data 8, Dup 0, Trail 13 : S60_AS_2
Item 1, Record 1514, Data 4, Dup 4, Trail 13 : S60_FN_1
Item 2, Record 1515, Data 3, Dup 8, Trail 10 : S60_FN_1_TD
Item 3, Record 1516, Data 1, Dup 10, Trail 10 : S60_FN_1_TS
.
.
Item 45, Record 1434, Data 2, Dup 7, Trail 12 : SA40_SSPF
.
.
Item 68, Record 1794, Data 1, Dup 11, Trail 9 : SA50_FP_2_TS
.
.
Item 71, Record 1795, Data 1, Dup 6, Trail 14 : SA50_FX
Item 72, Record 1798, Data 4, Dup 7, Trail 10 : SA50_FX1000
Item 73, Record 1799, Data 3, Dup 11, Trail 7 : SA50_FX1000_TD
Item 74, Record 2033, Data 2, Dup 14, Trail 5 : SA50_FX1000_TD_Z
Item 75, Record 1800, Data 1, Dup 13, Trail 7 : SA50_FX1000_TS
Item 76, Record 2035, Data 2, Dup 14, Trail 5 : SA50_FX1000_TS_Z
Item 77, Record 2031, Data 1, Dup 12, Trail 8 : SA50_FX1000_Z
Item 78, Record 1796, Data 3, Dup 7, Trail 11 : SA50_FX_TD
Item 79, Record 2032, Data 2, Dup 10, Trail 9 : SA50_FX_TD_Z
Item 80, Record 1797, Data 1, Dup 9, Trail 11 : SA50_FX_TS
Item 81, Record 2034, Data 2, Dup 10, Trail 9 : SA50_FX_TS_Z
Item 82, Record 2030, Data 1, Dup 8, Trail 12 : SA50_FX_Z
Item 83, Record 1801, Data 3, Dup 5, Trail 13 : SA50_P_1
Item 84, Record 1802, Data 1, Dup 7, Trail 13 : SA50_P_2
Item 85, Record 1803, Data 4, Dup 5, Trail 12 : SA50_SSFN
Item 86, Record 1804, Data 2, Dup 7, Trail 12 : SA50_SSPF
.
Item 88, Record 1545, Data 4, Dup 5, Trail 12 : SA60_FN_1
Item 89, Record 1546, Data 3, Dup 9, Trail 9 : SA60_FN_1_TD
Item 90, Record 1547, Data 1, Dup 11, Trail 9 : SA60_FN_1_TS
Right page reference 004000{/source}
Page 003E00 is a "Leaf page" so our search ends here. This page has both a page to the left (003E00) and a page to the right (004000), but that is not relevant now.
Keys are stored in "compressed" mode in CDX.
Each key takes 3 Data bytes on this page and a key value. The data bytes store the record number, # of duplicate bytes and # of trailing bytes.
These 24 bits per record are divided into 14 bits for the record number and 5 bits for the # of duplicate and trailing bytes (the index expression is 21 characters long, so we need at least 5 bits to represent a number between 0 and 21).
The key list shows that the first key has 8 unique data bytes and 13 trailing spaces
The second key has 4 duplicate characters that are the same as the first key (S60_) and 13 trailing spaces. So the index only stores the 4 unique characters (FN_1).
The third key has 8 duplicate characters (S60_FN_1) and 10 trailing spaces. So only 3 unique characters are stored in the page (_TD) and so on and so on.
As a result the number of keys on a leaf page can become quite large and is never fixed. This is one of the "challenges" of the CDX format.
Especially when an index page has many duplicate keys (for example invoice dates) then the page contains mainly record numbers and a flag that indicates that all bytes are duplicates from the previous key).
Btw: if you have a problem understanding this and when you wonder why they made this so complicated: the algorithm was invented in the DOS days when memory and disk space were a limiting factor and when critical code was written in assembly code so this was very fast.
And remember how it was for us to code this !
As you can see the key SA50_FX1000 is the key for Item 72.
For performance reasons X# does not read this page from start to end (for this page that would take an average of 91 / 2 = 45 comparisons).
We use a binary search (an average of SQrt(91) = 9,5 comparisons).
The test program both in VO and X# did not use SetCollation(), so was using the normal Windows string comparisons.
Item 45 -> smaller
Item 68 -> smaller
Item 80 -> smaller (in the Windows collation the "_" is sorted before the "0")
Item 86 -> larger
Item 83 -> larger
Item 82 -> smaller
So after 6 comparisons we have found that the key was expected between 82 and 83 and was not in the index.
By why did VO find the record and X# not:
Apparently VO is doing a linear search on the index page and it finds the key.
When we changed the VO test program and tried to search for "SA50_FX_TD" then the VO test program also failed!
What did we learn
The lesson learned here is to ALWAYS use the same settings for sorting both on the machine where the index is created as on the machine where it is used.
It does not matter if the program using the file is not changing the file. The only thing that would work reliably without setting the collations is a GoTop followed by a set of skips until EOF. You can probably figure out yourself why that would work.
So either use SetCollation(#Clipper) and a nation module, or use SetCollation(#Windows) and use SetAppLocaleId() to set the machines to the same collation.
My customer was under the impression that this collation information was stored in the index file, but unfortunately this is NOT stored. At least not in the DBFNTX format and in the DBFCDX format that we are using, which matches the FoxPro 2.6 file format.
What about FoxPro
FoxPro of course had to deal with the same problems that VO had to deal with. FoxPro also uses the "Codepage" byte in the file header to mark the Windows codepage with which the file was created.
For indexes FoxPro has introduced a new mechanism that was never picked up in VO. Neither did VO pick up the new FoxPro field types such as Integer, DateTime etc.
Foxpro has introduced collations and it stores the name of the collation used to sort the index in the header of each tag.
{source}INDEX ON eExpression TO IDXFileName | TAG TagName [BINARY]
[COLLATE cCollateSequence] [OF CDXFileName] [FOR lExpression]
[COMPACT] [ASCENDING | DESCENDING] [UNIQUE | CANDIDATE] [ADDITIVE]{/source}
These collations have names such as GENERAL, MACHINE, GERMAN and DUTCH.
For each of these collations there is a a comparison table in te FoxPro runtime. Sometimes there are more table per language, such as GERMAN_437 and GERMAN_1252.
There are also collations for asian languages such as PINYIN, KOREAN, STROKE, JAPANESE. There are no string tables for these languages. As far as I know these languages will use the windows CompareString() routine that VO uses in #Windows mode to compare strings.
Most of these languages are "multi byte" by the way, so many characters require more than one byte to store. A 20 byte string may contain only 10 Chinese characters.
FoxPro even allows to comine tags with different collations in the same CDX file.
If you open a table in FoxPro (also in X# with the DBFVFP RDD) then this information is read and this collation table is used for the string comparisons for seeks and index creation.
In X# we have stored the FoxPro collation tables as managed resource in the XSharp.RDD assembly.
They are actually quite complicated and not simply a 1-1 translation. Sometimes 1 character is replaced with a single byte. But there are also languages where 2 characters in a row are translated in a single byte for the index or where a single character is written as 2 (Æ could be written in the index as AE).
And of course this is not publicly documented at all....
Should we make changes to the index format to help prevent the problems ?
We could do something similar for the DBFCDX driver and store a collation "WINDOWS" when you created it with SetCollation(Windows) or otherwise the name of the nation module (GERMAN, DUTCH etc). It would certainly make sense when the only applications that access the file are X# applications. But VO apps would ignore that and would keep on using the global collation
But if there are enough people that would like this, then we can do that.
I hope you found this of interest.
Robert
Made me look into my code, and i found, i use SetNatDll, but pointing to the original German.dll of VO2838... Is this ok?
THX
Karl
So I think you're fine regarding this, but probably better use the "new" file, in order to have the latest texts as well. Btw, in the X# runtime the path to the file is being ignored, the weight table gets loaded always from a resource inside the X# runtime dlls.
This shows again the high level of your support.
Wolfgang